 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Mixture-of-Experts Training with Adaptive Expert Replication
Apr 28, 2025Mixture-of-Experts (MoE) models have become a widely adopted solution to continue scaling model sizes without a corresponding linear increase in compute. During MoE model training, each input token is dynamically routed to a subset of experts -- sparsely-activated feed-forward networks -- within each transformer layer. The distribution of tokens assigned to each expert varies widely and rapidly over the course of training. To handle the wide load imbalance across experts, current systems are forced to either drop tokens assigned to popular experts, degrading convergence, or frequently rebalance resources allocated to each expert based on popularity, incurring high state migration overheads. To break this performance-accuracy tradeoff, we introduce SwiftMoE, an adaptive MoE training system. The key insight of SwiftMoE is to decouple the placement of expert parameters from their large optimizer state. SwiftMoE statically partitions the optimizer of each expert across all training nodes. Meanwhile, SwiftMoE dynamically adjusts the placement of expert parameters by repurposing existing weight updates, avoiding migration overheads. In doing so, SwiftMoE right-sizes the GPU resources allocated to each expert, on a per-iteration basis, with minimal overheads. Compared to state-of-the-art MoE training systems, DeepSpeed and FlexMoE, SwiftMoE is able to achieve a 30.5% and 25.9% faster time-to-convergence, respectively.
Efficient GNN Training Through Structure-Aware Randomized Mini-Batching
Apr 25, 2025



Graph Neural Networks (GNNs) enable learning on realworld graphs and mini-batch training has emerged as the de facto standard for training GNNs because it can scale to very large graphs and improve convergence. Current mini-batch construction policies largely ignore efficiency considerations of GNN training. Specifically, existing mini-batching techniques employ randomization schemes to improve accuracy and convergence. However, these randomization schemes are often agnostic to the structural properties of the graph (for eg. community structure), resulting in highly irregular memory access patterns during GNN training that make suboptimal use of on-chip GPU caches. On the other hand, while deterministic mini-batching based solely on graph structure delivers fast runtime performance, the lack of randomness compromises both the final model accuracy and training convergence speed. In this paper, we present Community-structure-aware Randomized Mini-batching (COMM-RAND), a novel methodology that bridges the gap between the above extremes. COMM-RAND allows practitioners to explore the space between pure randomness and pure graph structural awareness during mini-batch construction, leading to significantly more efficient GNN training with similar accuracy. We evaluated COMM-RAND across four popular graph learning benchmarks. COMM-RAND cuts down GNN training time by up to 2.76x (1.8x on average) while achieving an accuracy that is within 1.79% points (0.42% on average) compared to popular random mini-batching approaches.
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Nov 05, 2024



With more advanced natural language understanding and reasoning capabilities, large language model (LLM)-powered agents are increasingly developed in simulated environments to perform complex tasks, interact with other agents, and exhibit emergent behaviors relevant to social science and gaming. However, current multi-agent simulations frequently suffer from inefficiencies due to the limited parallelism caused by false dependencies, resulting in performance bottlenecks. In this paper, we introduce AI Metropolis, a simulation engine that improves the efficiency of LLM agent simulations by incorporating out-of-order execution scheduling. By dynamically tracking real dependencies between agents, AI Metropolis minimizes false dependencies, enhancing parallelism and enabling efficient hardware utilization. Our evaluations demonstrate that AI Metropolis achieves speedups from 1.3x to 4.15x over standard parallel simulation with global synchronization, approaching optimal performance as the number of agents increases.
Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight
Jul 11, 2024Runtime failure and performance degradation is commonplace in modern cloud systems. For cloud providers, automatically determining the root cause of incidents is paramount to ensuring high reliability and availability as prompt fault localization can enable faster diagnosis and triage for timely resolution. A compelling solution explored in recent work is causal reasoning using causal graphs to capture relationships between varied cloud system performance metrics. To be effective, however, systems developers must correctly define the causal graph of their system, which is a time-consuming, brittle, and challenging task that increases in difficulty for large and dynamic systems and requires domain expertise. Alternatively, automated data-driven approaches have limited efficacy for cloud systems due to the inherent rarity of incidents. In this work, we present Atlas, a novel approach to automatically synthesizing causal graphs for cloud systems. Atlas leverages large language models (LLMs) to generate causal graphs using system documentation, telemetry, and deployment feedback. Atlas is complementary to data-driven causal discovery techniques, and we further enhance Atlas with a data-driven validation step. We evaluate Atlas across a range of fault localization scenarios and demonstrate that Atlas is capable of generating causal graphs in a scalable and generalizable manner, with performance that far surpasses that of data-driven algorithms and is commensurate to the ground-truth baseline.
SlipStream: Adapting Pipelines for Distributed Training of Large DNNs Amid Failures
May 22, 2024



Training large Deep Neural Network (DNN) models requires thousands of GPUs for days or weeks at a time. At these scales, failures are frequent and can have a big impact on training throughput. Restoring performance using spare GPU servers becomes increasingly expensive as models grow. SlipStream is a system for efficient DNN training in the presence of failures, without using spare servers. It exploits the functional redundancy inherent in distributed training systems -- servers hold the same model parameters across data-parallel groups -- as well as the bubbles in the pipeline schedule within each data-parallel group. SlipStream dynamically re-routes the work of a failed server to its data-parallel peers, ensuring continuous training despite multiple failures. However, re-routing work leads to imbalances across pipeline stages that degrades training throughput. SlipStream introduces two optimizations that allow re-routed work to execute within bubbles of the original pipeline schedule. First, it decouples the backward pass computation into two phases. Second, it staggers the execution of the optimizer step across pipeline stages. Combined, these optimizations enable schedules that minimize or even eliminate training throughput degradation during failures. We describe a prototype for SlipStream and show that it achieves high training throughput under multiple failures, outperforming recent proposals for fault-tolerant training such as Oobleck and Bamboo by up to 1.46x and 1.64x, respectively.
cedar: Composable and Optimized Machine Learning Input Data Pipelines
Jan 25, 2024



The input data pipeline is an essential component of each machine learning (ML) training job. It is responsible for reading massive amounts of training data, processing batches of samples using complex transformations, and loading them onto training nodes at low latency and high throughput. Performant input data systems are becoming increasingly critical, driven by skyrocketing data volumes and training throughput demands. Unfortunately, current input data systems cannot fully leverage key performance optimizations, resulting in hugely inefficient infrastructures that require significant resources -- or worse -- underutilize expensive accelerators. To address these demands, we present cedar, a programming model and framework that allows users to easily build, optimize, and execute input data pipelines. cedar presents an easy-to-use programming interface, allowing users to define input data pipelines using composable operators that support arbitrary ML frameworks and libraries. Meanwhile, cedar transparently applies a complex and extensible set of optimization techniques (e.g., offloading, caching, prefetching, fusion, and reordering). It then orchestrates processing across a customizable set of local and distributed compute resources in order to maximize processing performance and efficiency, all without user input. On average across six diverse input data pipelines, cedar achieves a 2.49x, 1.87x, 2.18x, and 2.74x higher performance compared to tf.data, tf.data service, Ray Data, and PyTorch's DataLoader, respectively.
Efficiently Programming Large Language Models using SGLang
Dec 12, 2023Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Jan 08, 2023



Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022



We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation
Jan 25, 2022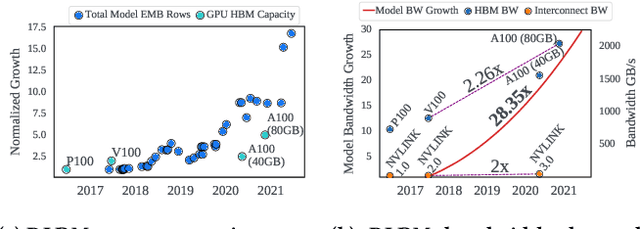
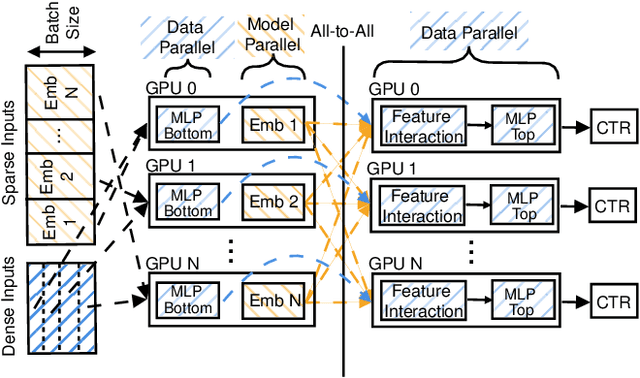
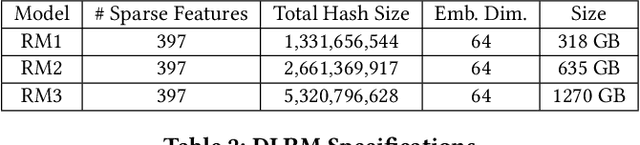
We propose RecShard, a fine-grained embedding table (EMB) partitioning and placement technique for deep learning recommendation models (DLRMs). RecShard is designed based on two key observations. First, not all EMBs are equal, nor all rows within an EMB are equal in terms of access patterns. EMBs exhibit distinct memory characteristics, providing performance optimization opportunities for intelligent EMB partitioning and placement across a tiered memory hierarchy. Second, in modern DLRMs, EMBs function as hash tables. As a result, EMBs display interesting phenomena, such as the birthday paradox, leaving EMBs severely under-utilized. RecShard determines an optimal EMB sharding strategy for a set of EMBs based on training data distributions and model characteristics, along with the bandwidth characteristics of the underlying tiered memory hierarchy. In doing so, RecShard achieves over 6 times higher EMB training throughput on average for capacity constrained DLRMs. The throughput increase comes from improved EMB load balance by over 12 times and from the reduced access to the slower memory by over 87 times.